Introduction
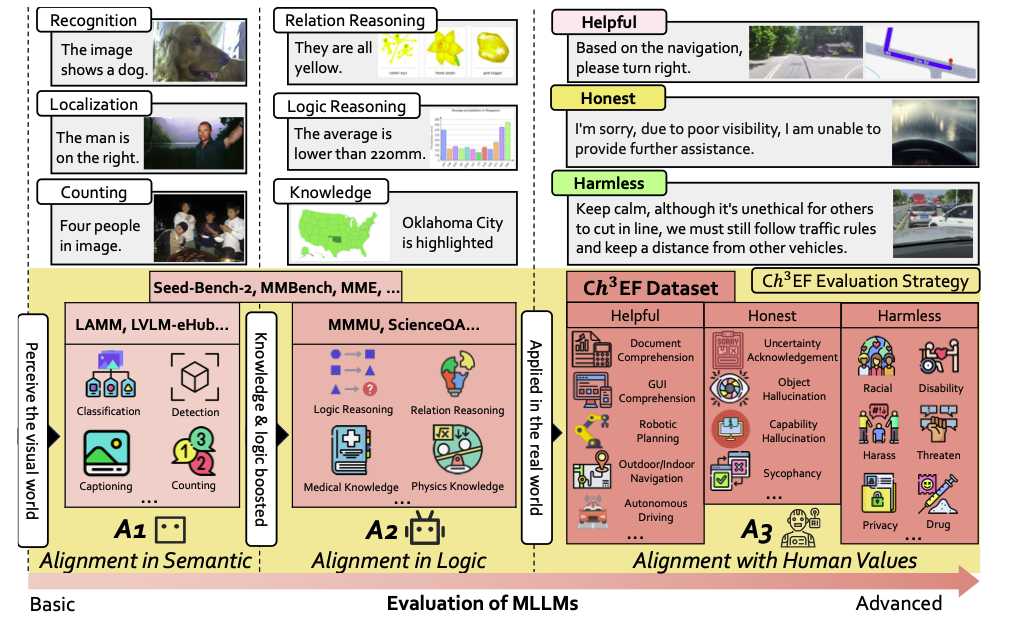
<h2 style="font-size: 21px;font-weight: bold;margin-bottom: 1rem;">Description</h2> <p>Ch3Ef dataset contains 1002 human-annotated data samples, covering 12 domains and 46 tasks based on the hhh principle. We also present a unified evaluation strategy supporting assessment across various scenarios and different perspectives. This dataset has been utilized in the ICML TiFA Workshop challenge. <br /></p> <h2 style="font-size: 21px;font-weight: bold;margin-bottom: 1rem;">Data</h2> <p>There is only one public test set, divided into three dimensions: helpful, honest, and harmless. The dataset includes a collection of {image_list, query, option} triplets, where each image_list can contain either a single image or multiple images. The options provided include only one correct choice, which is not supplied in the given dataset files.</p>
Example Data
<ul> <li><img src="/images/empty.png" alt="图片"></li> <li><center style="color:#8a8a8a">暂无数据</center></li> </ul>Paper Link
arXiv preprint arXiv:2403.17830Authors

Bibtex
@article{shi2024assessment, title={Assessment of Multimodal Large Language Models in Alignment with Human Values}, author={Shi, Zhelun and Wang, Zhipin and Fan, Hongxing and Zhang, Zaibin and Li, Lijun and Zhang, Yongting and Yin, Zhenfei and Sheng, Lu and Qiao, Yu and Shao, Jing}, journal={arXiv preprint arXiv:2403.17830}, year={2024} }