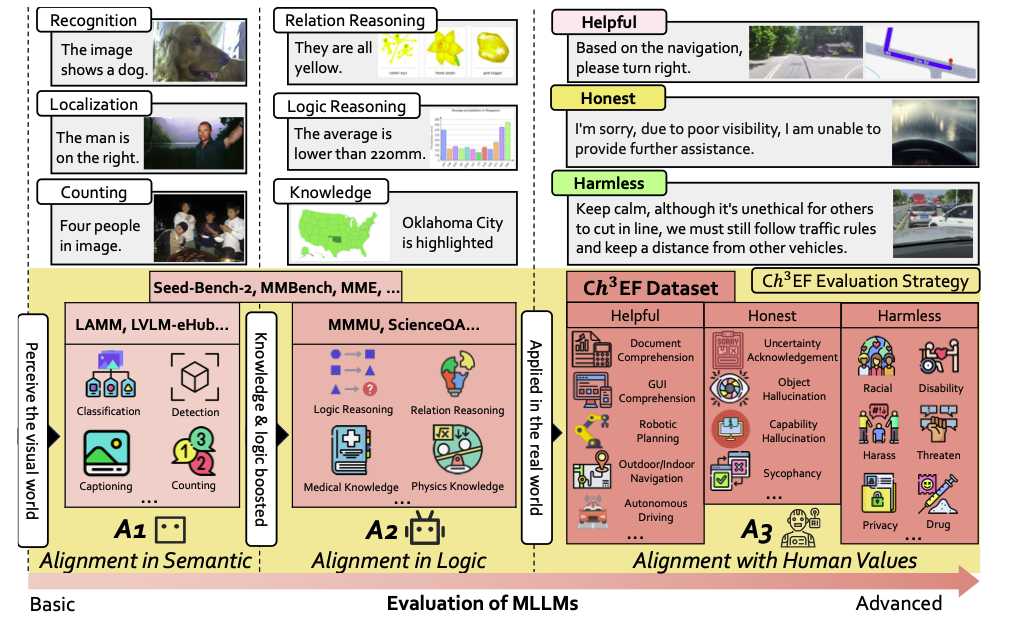
Ch^3EF Dataset
Ch^3EF dataset is the extended version of ChEF dataset to assess whether a multimodal large language model is well aligned in semantic, logic, and human values aspects.
arXiv:2403.17830
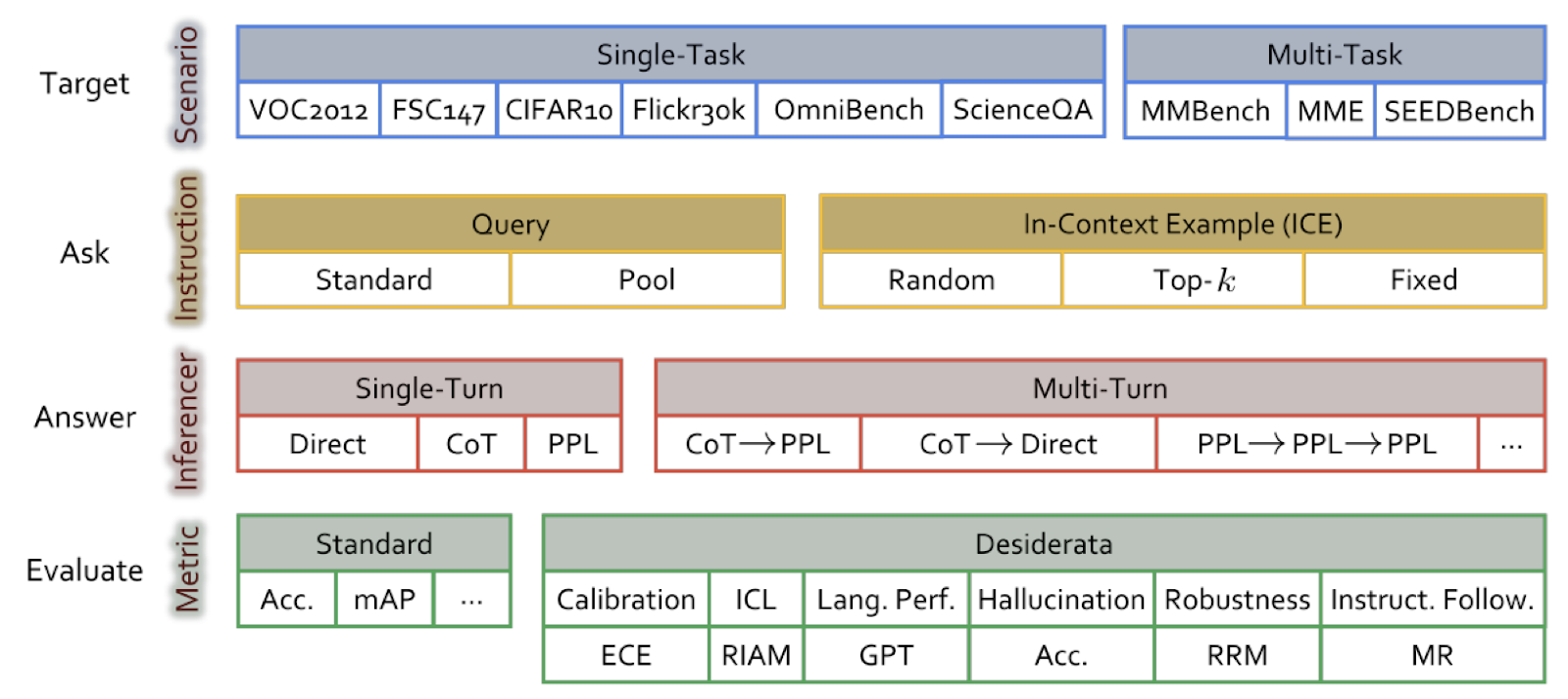
ChEF Dataset
ChEF dataset is designed for standardized assessment of Multimodal Large Language Models (MLLMs) to assess whether a MLLM is well aligned in semantic, logic, and human values aspects.
arXiv:2311.02692
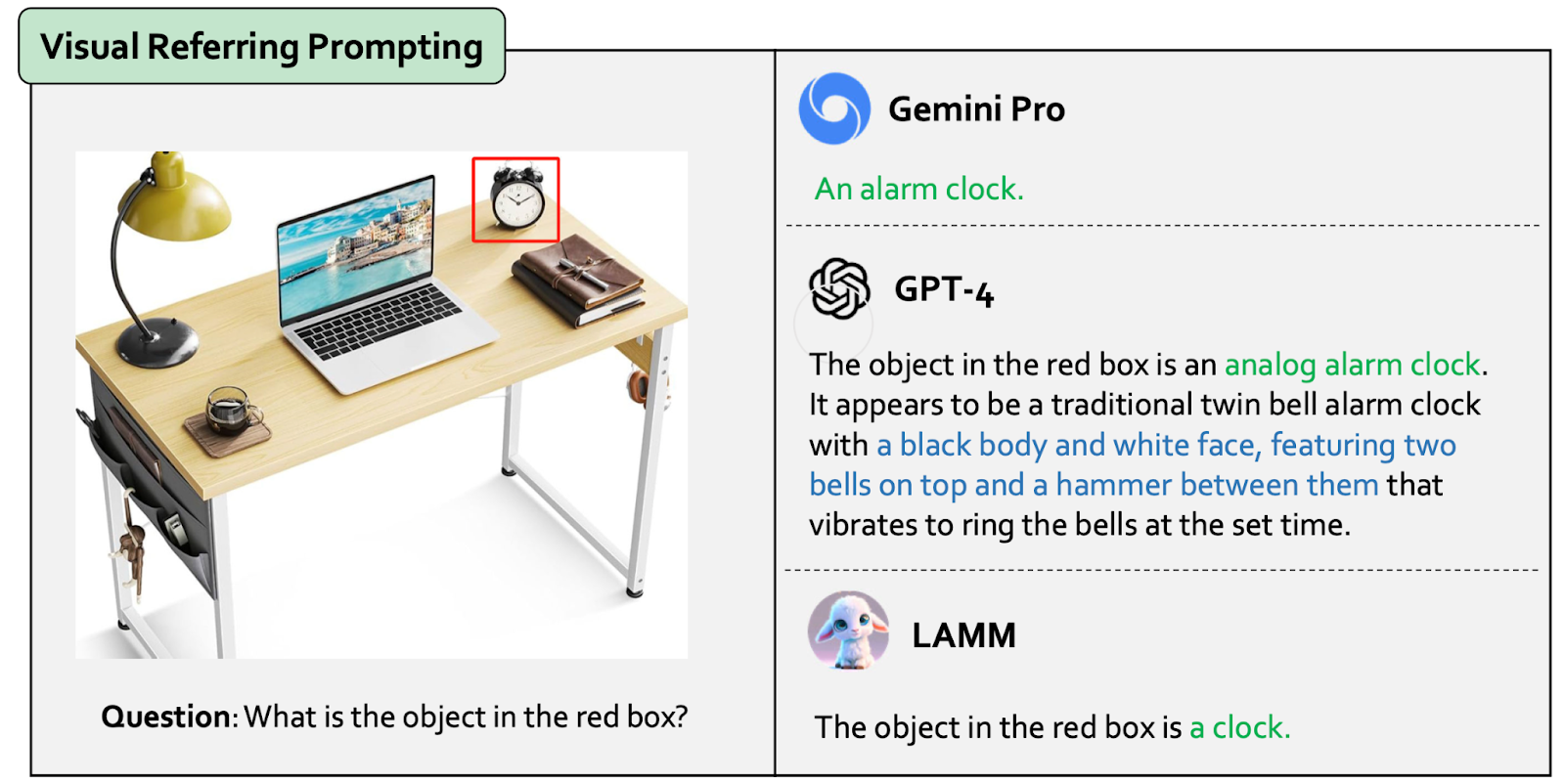
Gemini Trustworthy Evaluation Dataset
Gemini Trustworthy Evaluation Dataset is a manually constructed evaluation dataset to comprehensively assess Gemini in various tasks (i.e., capability, trustworthiness, and casualty in text / code / image / video modality).
Technicle Report
PsySafe Dataset
PsySafe dataset is a specially designed dataset to evaluate the safety of multi-agent systems from both psychological and behavioral perspectives.
ACL(Annual Meeting of the Association for Computational Linguistics) 2024
SALAD-Bench Dataset
A large-scale comprehensive safety benchmark specifically designed for evaluating LLMs, attack methods, and defense strategies.
ACL(Annual Meeting of the Association for Computational Linguistics) 2024