Introduction
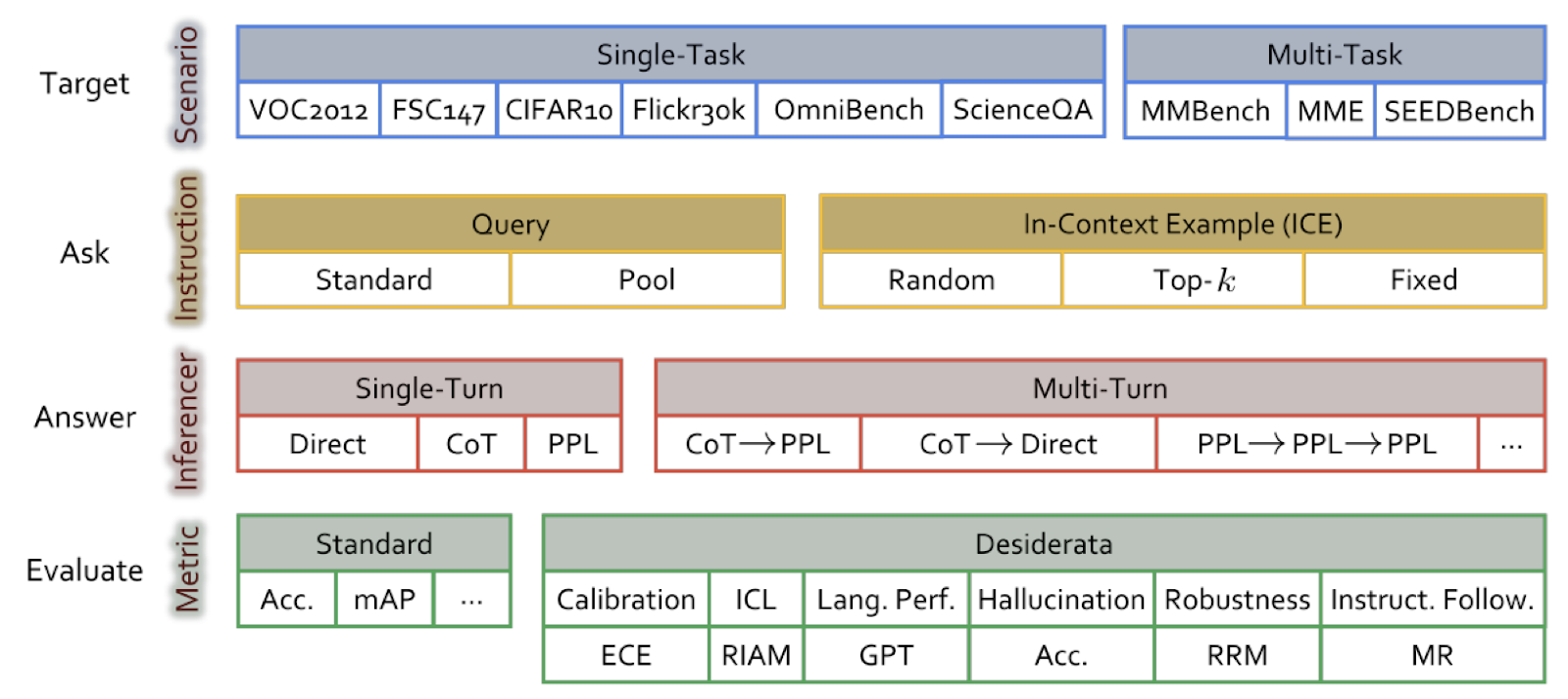
<h2>Overview</h2> <p>The Comprehensive Evaluation Framework (ChEF) is designed for standardized assessment of Multimodal Large Language Models (MLLMs). It consists of four modular components:</p> <h3>Components</h3> <ul> <li><strong>Scenario</strong>: A collection of scalable multimodal datasets for various tasks such as image classification, object detection, and multimodal question-answering.</li> <li><strong>Instruction</strong>: Flexible methods for posing questions and setting instruction examples to MLLMs, including in-context example (ICE) retrieving strategies for in-context learning (ICL).</li> <li><strong>Inferencer</strong>: Reliable question-answering strategies, such as Direct, Perplexity (PPL), and Chain-of-Thought (CoT) prompting.</li> <li><strong>Metric</strong>: Task-specific score functions to evaluate MLLM performance, including accuracy, mAP, BLEU, Expected Calibration Error (ECE), and GPT-based metrics.</li> </ul> <h2>Main Findings</h2> <h3>Evaluation Coverage</h3> <ul> <li>ChEF offers a standardized framework to comprehensively profile MLLMs and compare different models.</li> <li>It supports versatile evaluations through systematic selection of the four components, enabling new evaluations by designing new Recipes.</li> </ul> <h3>Six New Recipes</h3> <ol> <li><strong>Calibration</strong>: Measures uncertainty and confidence.</li> <li><strong>In-context Learning</strong>: Assesses the ability to learn from instruction examples.</li> <li><strong>Instruction Following</strong>: Evaluates adherence to instructions.</li> <li><strong>Language Performance</strong>: Checks the readability of generated descriptions.</li> <li><strong>Hallucination</strong>: Ensures the model does not mention nonexistent objects.</li> <li><strong>Robustness</strong>: Tests resilience to input corruptions.</li> </ol> <h3>Evaluation Results</h3> <ul> <li>Conducted on 9 prominent MLLMs across 9 scenarios and 6 desiderata.</li> <li>Recent MLLMs struggle to perform well across all scenarios, indicating a tug-of-war issue between tasks.</li> <li>Significant difficulties in in-context learning, instruction following, and robustness, highlighting limitations in real-world multimodal interactions.</li> <li>Strong correlation found between desiderata and visual performance, revealing intrinsic properties required for effective multimodal interactions.</li> </ul> <h2>Conclusion</h2> <p>ChEF provides a comprehensive and scalable framework for evaluating the capabilities and limitations of MLLMs, contributing to a deeper understanding and improvement of these models in multimodal tasks.</p>
Example Data
<ul> <li><img src="/images/empty.png" alt="图片"></li> <li><center style="color:#8a8a8a">暂无数据</center></li> </ul>Paper Link
arXiv:2311.02692Authors

Bibtex
@misc{shi2023chefcomprehensiveevaluationframework, title={ChEF: A Comprehensive Evaluation Framework for Standardized Assessment of Multimodal Large Language Models}, author={Zhelun Shi and Zhipin Wang and Hongxing Fan and Zhenfei Yin and Lu Sheng and Yu Qiao and Jing Shao}, year={2023}, eprint={2311.02692}, archivePrefix={arXiv}, primaryClass={cs.CV} url={https://arxiv.org/abs/2311.02692}, }