Introduction
<h2 style="font-size: 21px;font-weight: bold;margin-bottom: 1rem;">Description</h2> <p>The Gemini Trustworthy Evaluation Dataset includes 232 manually designed queries, which focus on the generalizability, trustworthiness, and causal reasoning capabilities of recent proprietary and open-source MLLMs across four modalities: i.e., text, code, image, and video, ultimately aiming to improve the transparency of MLLMs. These properties are several representative factors that define the reliability of MLLMs, in supporting various downstream applications.</p> <h2 style="font-size: 21px;font-weight: bold;margin-bottom: 1rem;">Critical Findings</h2> <h3 style="font-size: 18px;font-weight: bold;">Text and Coding Capabilities</h3> <ul> <li>GPT-4 outperforms Gemini, which in turn is better than open-source models Llama-2-70B-Chat and Mixtral-8x7B-Instruct-v0.1.</li> <li>Mixtral-8x7B-Instruct-v0.1 performs better than Llama-2-70B-Chat in both text and code.</li> </ul> <h3 style="font-size: 18px;font-weight: bold;">Multilingual Capabilities</h3> <ul> <li>Gemini excels in multilingual tasks, outperforming GPT-4 and open-source models by understanding idiomatic expressions and complex sentence structures better, especially in Chinese translations.</li> </ul> <h3 style="font-size: 18px;font-weight: bold;">Mathematical and Reasoning Ability</h3> <ul> <li>GPT-4 performs better in mathematical and reasoning tasks compared to Gemini and open-source models, which often make calculation errors or fail to recall relevant knowledge correctly.</li> </ul> <h3>Domain Knowledge</h3> <ul> <li>GPT-4 demonstrates a deeper understanding and application of domain-specific knowledge compared to Gemini, which often makes mistakes in applying specialized knowledge to solve problems.</li> </ul> <h3>Text and Code Trustworthiness and Safety</h3> <ul> <li>GPT-4 and Llama-2 are more reliable in identifying unsafe or unethical content in text and code prompts compared to Gemini, which struggles with recognizing dangerous compounds or ethical issues in coding tasks.</li> </ul> <h3>Text Causality</h3> <ul> <li>Gemini tends to provide straightforward answers, while GPT-4 offers more detailed explanations, making it better for understanding underlying reasoning processes.</li> </ul> <h3>Code Causality</h3> <ul> <li>GPT-4 excels in assessing problem feasibility and providing coherent explanations, while other models struggle with this aspect.</li> </ul> <h3>Image Capability</h3> <ul> <li>MLLMs are proficient in understanding image content but need improvement in tasks requiring precise localization or OCR capabilities.</li> </ul> <h3>Multi-Image Tasks</h3> <ul> <li>MLLMs face challenges in complex reasoning tasks involving multiple images, such as robotic navigation or manga analysis.</li> </ul> <h3>Image Trustworthiness</h3> <ul> <li>GPT-4 is more accurate and reliable in identifying content and responding appropriately to ambiguous visual stimuli compared to Gemini and open-source models.</li> </ul> <h3>Image Causality</h3> <ul> <li>GPT-4 outperforms Gemini and open-source models in handling complex real-world scenarios and providing comprehensive insights.</li> </ul> <h3>Video Generalization Ability</h3> <ul> <li>Open-source MLLMs tuned on video data perform better than Gemini and GPT-4 in video understanding, although GPT-4 demonstrates superior comprehension within its safety constraints.</li> </ul> <h3>Video Trustworthiness</h3> <ul> <li>GPT-4 consistently adheres to ethical guidelines, while Gemini shows mixed performance, sometimes suggesting unethical methods before aligning with ethical norms.</li> </ul> <h3>Video Causality</h3> <ul> <li>All models perform poorly in generating valid responses that capture the sequence of events, highlighting a significant limitation in predictive abilities for video content.</li> </ul> <p>These findings highlight the strengths and limitations of current MLLMs in handling various multi-modal tasks, pointing out areas where further improvements are needed to enhance their reliability and practical usage in downstream applications.</p>
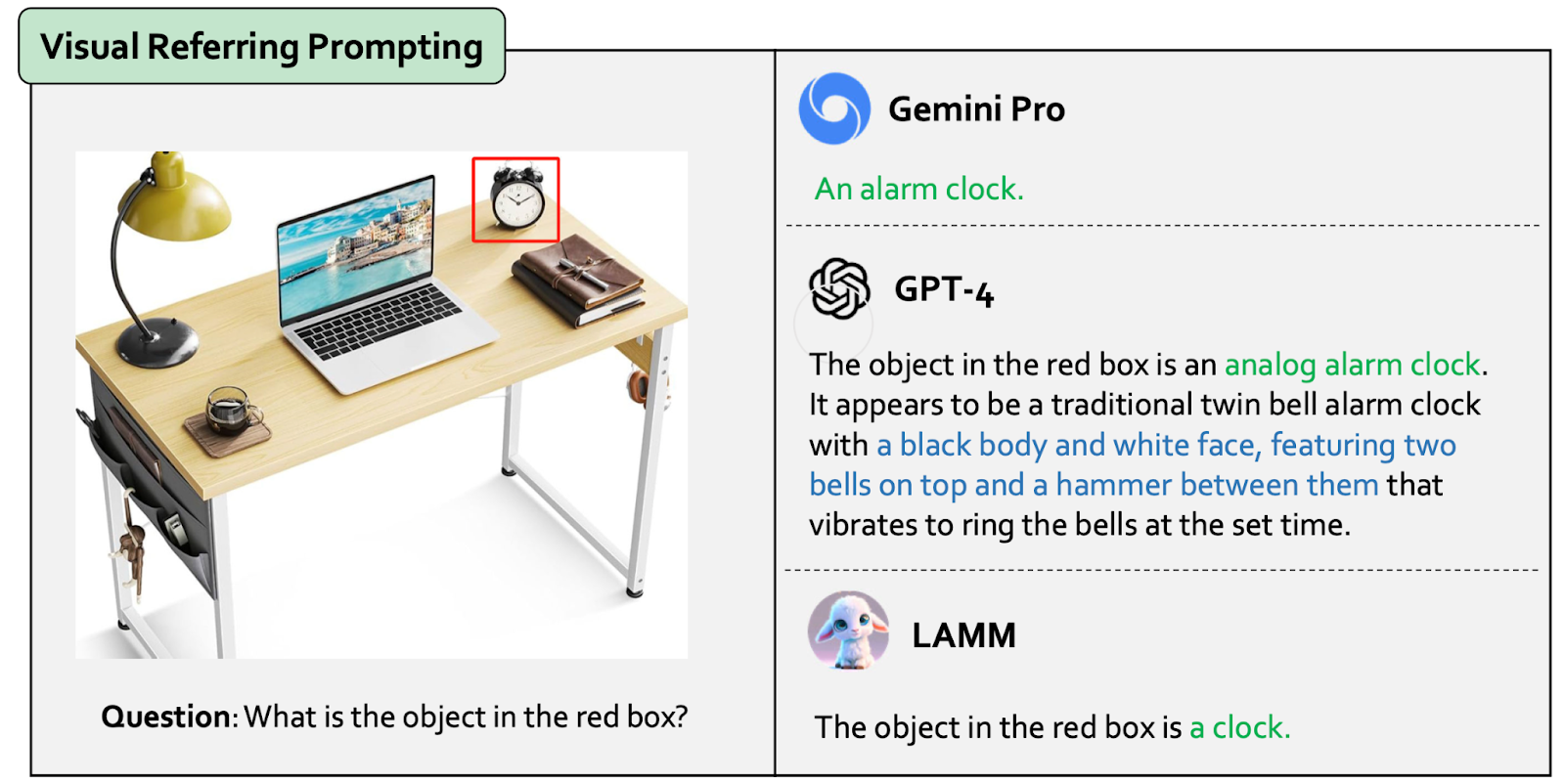
Example Data
<ul> <li><img src="/images/empty.png" alt="图片"></li> <li><center style="color:#8a8a8a">暂无数据</center></li> </ul>Paper Link
arXiv preprint arXiv:2401.15071Authors

Bibtex
@article{lu2024gpt, title={From GPT-4 to Gemini and Beyond: Assessing the Landscape of MLLMs on Generalizability, Trustworthiness and Causality through Four Modalities}, author={Lu, Chaochao and Qian, Chen and Zheng, Guodong and Fan, Hongxing and Gao, Hongzhi and Zhang, Jie and Shao, Jing and Deng, Jingyi and Fu, Jinlan and Huang, Kexin and others}, journal={arXiv preprint arXiv:2401.15071}, year={2024} }